Hi HN! We're Evgeny and Arjun, and we’re building a better way to do analytics with Postgres.
We love Postgres for its simplicity, power, and rich ecosystem. But engineers have to still get bogged down with heavyweight and expensive OLAP systems when connecting an analytics data stack.
Postgres is amazing at OLTP queries, but not for OLAP queries (large data scans and aggregations). Even in this case, we’ve still heard from countless scaling startups that they still try to use only a read replica to run analytics workloads since they don’t want to deal with the data engineering complexity of the alternative. This actually works surprising well initially, but starts to break for them as they scale or when integrating multiple data sources. Adding lots of indexes to support analytics also slows down their transactional write performance.
When growing out of “just use Postgres”, companies have to understand and wrangle complex ETL pipelines, CDC processes, and data warehouses — adding layers of complexity that defeat the simplicity that undermines their initial choice for Postgres as their data storage in the first place.
We thought there had to be a better way, so we’re building BemiDB. It’s designed to handle complex analytical queries at scale without the usual overhead. It’s a single binary that automatically syncs with Postgres data and is Postgres-compatible, so it’s like querying standard Postgres and works with all existing tools.
Under the hood, we use Apache Iceberg (with Parquet data files) stored in S3. This allows for bottomless inexpensive storage, compressed data in columnar files, and an open format that guarantees compatibility with other data tools.
We embed DuckDB as the query engine for in-memory analytics that work for complex queries. With efficient columnar storage and vectorized execution, we’re aiming for faster results without heavy infra. BemiDB communicates over the Postgres wire protocol to make all querying Postgres-compatible.
We want to simplify data stacks for companies that use Postgres by reducing complexity (single binary and S3), using non-proprietary data formats (Iceberg open tables), and removing vendor lock-in (open source). We'd love to hear your feedback! What do you think?
Comments URL: https://news.ycombinator.com/item?id=42078067
Points: 48
# Comments: 22
Melden Sie sich an, um einen Kommentar hinzuzufügen
Andere Beiträge in dieser Gruppe


I'm lost between ChatGPT vs Claude vs Gemini... which subscriptions to take? With Cursor and all these specific AI tools, I just wanted one simple chat app where I can use any model and pay only w


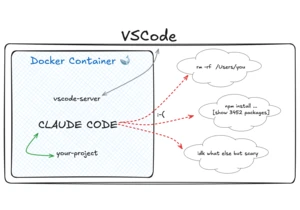
Article URL: https://timsh.org/claude-inside-docker/
Comments URL: https://news

Article URL: https://hillspace.justindujardin.com/
Comments URL: https://news.yco
