AI companies claim their tools couldn't exist without training on copyrighted material. It turns out, they could — it's just really hard. To prove it, AI researchers trained a new model that's less powerful but much more ethical. That's because the LLM's dataset uses only public domain and openly licensed material.
The paper (via The Washington Post) was a collaboration between 14 different institutions. The authors represent universities like MIT, Carnegie Mellon and the University of Toronto. Nonprofits like Vector Institute and the Allen Institute for AI also contributed.
The group built an 8 TB ethically-sourced dataset. Among the data was a set of 130,000 books in the Library of Congress. After inputting the material, they trained a seven-billion-parameter large language model (LLM) on that data. The result? It performed about as well as Meta's similarly sized Llama 2-7B from 2023. The team didn't publish benchmarks comparing its results to today's top models.
Performance comparable to a two-year-old model wasn't the only downside. The process of putting it all together was also a grind. Much of the data couldn't be read by machines, so humans had to sift through it. "We use automated tools, but all of our stuff was manually annotated at the end of the day and checked by people," co-author Stella Biderman told WaPo. "And that's just really hard." Figuring out the legal details also made the process hard. The team had to determine which license applied to each website they scanned.
So, what do you do with a less powerful LLM that's much harder to train? If nothing else, it can serve as a counterpoint.
In 2024, OpenAI told a British parliamentary committee that such a model essentially couldn't exist. The company claimed it would be "impossible to train today's leading AI models without using copyrighted materials." Last year, an Anthropic expert witness added, "LLMs would likely not exist if AI firms were required to license the works in their training datasets."
Of course, this study won't change the trajectory of AI companies. After all, more work to create less powerful tools doesn't jive with their interests. But at least it punctures one of the industry's common arguments. Don't be surprised if you hear about this study again in legal cases and regulation arguments.
This article originally appeared on Engadget at https://www.engadget.com/ai/it-turns-out-you-can-train-ai-models-without-copyrighted-material-174016619.html?src=rss https://www.engadget.com/ai/it-turns-out-you-can-train-ai-models-without-copyrighted-material-174016619.html?src=rssMelden Sie sich an, um einen Kommentar hinzuzufügen
Andere Beiträge in dieser Gruppe
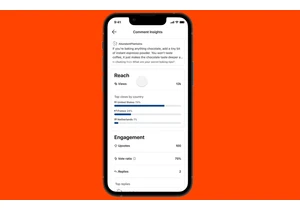
Reddit is making it easier to gauge the impact your comments are having. The company is introducing detailed analytics for comments that measure views and other engagement metrics. Reddit shared th

Google Cloud experienced outages today that led to disruptions for many online services. Report



We've been covering all the news Apple announced at
