



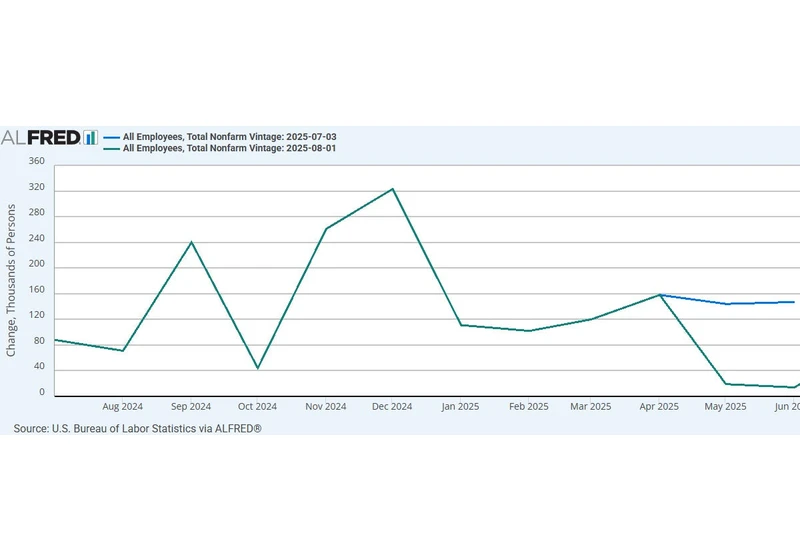
Article URL: https://stayathomemacro.substack.com/p/job-growth-has-slowed-sharply-the
Comments URL: https://news.ycombinator.com/item?id=44840428
Points: 56
# Comments: 47
https://stayathomemacro.substack.com/p/job-growth-has-slowed-sharply-the


Article URL: https://www.dbos.dev/blog/why-postgres-durable-execution
Comments URL: https://news.ycombinator.com/item?id=44840693
Points: 24
# Comments: 10

Sam said yesterday that chatgpt handles ~700M weekly users. Meanwhile, I can't even run a single GPT-4-class model locally without insane VRAM or painfully slow speeds.
Sure, they have huge GPU clusters, but there must be more going on - model optimizations, sharding, custom hardware, clever load balancing, etc.
What engineering tricks make this possible at such massive scale while keeping latency low?
Curious to hear insights from people who've built large-scale ML systems.
<

Article URL: https://inference.net/blog/what-s-left-is-distillation
Comments URL: https://news.ycombinator.com/item?id=44840746
Points: 18
# Comments: 1


Article URL: https://theahura.substack.com/p/tech-things-genies-lamp-openai-cant
Comments URL: https://news.ycombinator.com/item?id=44837646
Points: 129
# Comments: 39
https://theahura.substack.com/p/tech-things-genies-lamp-openai-cant

About a year ago I introduced Trayce to HN as the "network tab for docker containers". Now I have released a new version which adds an HTTP client. The idea is to combine network monitoring with an HTTP client to help developers interact with and debug web application servers.
Think "Burp Suite for developers".
Trayce stores requests as local files using the .bru file format. The UI is based on Flutter which means it offers a super-fast and modern desktop GUI with a total download size o

Article URL: https://elite-ai-assisted-coding.dev/p/copilot-agentic-coding-gpt-5-vs-claude-4-sonnet
Comments URL: https://news.ycombinator.com/item?id=44838303
Points: 133
# Comments: 97
https://elite-ai-assisted-coding.dev/p/copilot-agentic-coding-gpt-5-vs-claude-4-sonnet