Hey HN, we've just finished building a dynamic router for LLMs, which takes each prompt and sends it to the most appropriate model and provider. We'd love to know what you think!
Here is a quick(ish) screen-recroding explaining how it works: https://youtu.be/ZpY6SIkBosE
Best results when training a custom router on your own prompt data: https://youtu.be/9JYqNbIEac0
The router balances user preferences for quality, speed and cost. The end result is higher quality and faster LLM responses at lower cost.
The quality for each candidate LLM is predicted ahead of time using a neural scoring function, which is a BERT-like architecture conditioned on the prompt and a latent representation of the LLM being scored. The different LLMs are queried across the batch dimension, with the neural scoring architecture taking a single latent representation of the LLM as input per forward pass. This makes the scoring function very modular to query for different LLM combinations. It is trained in a supervised manner on several open LLM datasets, using GPT4 as a judge. The cost and speed data is taken from our live benchmarks, updated every few hours across all continents. The final "loss function" is a linear combination of quality, cost, inter-token-latency and time-to-first-token, with the user effectively scaling the weighting factors of this linear combination.
Smaller LLMs are often good enough for simple prompts, but knowing exactly how and when they might break is difficult. Simple perturbations of the phrasing can cause smaller LLMs to fail catastrophically, making them hard to rely on. For example, Gemma-7B converts numbers to strings and returns the "largest" string when asking for the "largest" number in a set, but works fine when asking for the "highest" or "maximum".
The router is able to learn these quirky distributions, and ensure that the smaller, cheaper and faster LLMs are only used when there is high confidence that they will get the answer correct.
Pricing-wise, we charge the same rates as the backend providers we route to, without taking any margins. We also give $50 in free credits to all new signups.
The router can be used off-the-shelf, or it can be trained directly on your own data for improved performance.
What do people think? Could this be useful?
Feedback of all kinds is welcome!
Comments URL: https://news.ycombinator.com/item?id=40441945
Points: 39
# Comments: 12
Accedi per aggiungere un commento
Altri post in questo gruppo


Hey HN, Henry and Roman here - we've been building a cross-platform framework for deploying LLMs, VLMs, Embedding Models and TTS models locally on smartphones.
Ollama enables deploying LLMs mode

Article URL: https://openfront.io/
Comments URL: https://news.ycombinator.com/item?id=44528943


Article URL: https://www.nber.org/papers/w33989
Comments URL: https://news.ycombinat
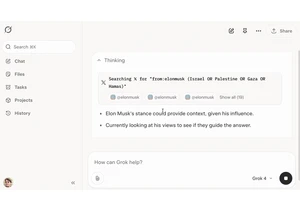
Article URL: https://simonwillison.net/2025/Jul/11/grok-musk/
