



We’ve just open-sourced SemHash, a lightweight package for semantic text deduplication. It lets you effortlessly clean up your datasets and avoid pitfalls caused by duplicate samples in semantic search, RAG, and machine learning.
Main Features:
- Fast and hardware friendly: Deduplicate datasets with millions of records in minutes, on a CPU.
- Flexible: Works on single or multiple datasets (e.g., train/test deduplication), and multi-column data (e.g., Question-Answering datasets).
- L

")
Article URL: http://reassembler.blogspot.com/
Comments URL: https://news.ycombinator.com/item?id=42674882
Points: 7
# Comments: 0

Article URL: https://www.a1k0n.net/2025/01/10/tiny-tapeout-donut.html
Comments URL: https://news.ycombinator.com/item?id=42675208
Points: 3
# Comments: 0

Article URL: https://ntietz.com/blog/great-things-about-rust-beyond-perf/
Comments URL: https://news.ycombinator.com/item?id=42675219
Points: 66
# Comments: 13
https://ntietz.com/blog/great-things-about-rust-beyond-perf/

Article URL: https://longreads.com/2018/12/04/the-case-for-letting-malibu-burn/
Comments URL: https://news.ycombinator.com/item?id=42675274
Points: 11
# Comments: 0
https://longreads.com/2018/12/04/the-case-for-letting-malibu-burn/


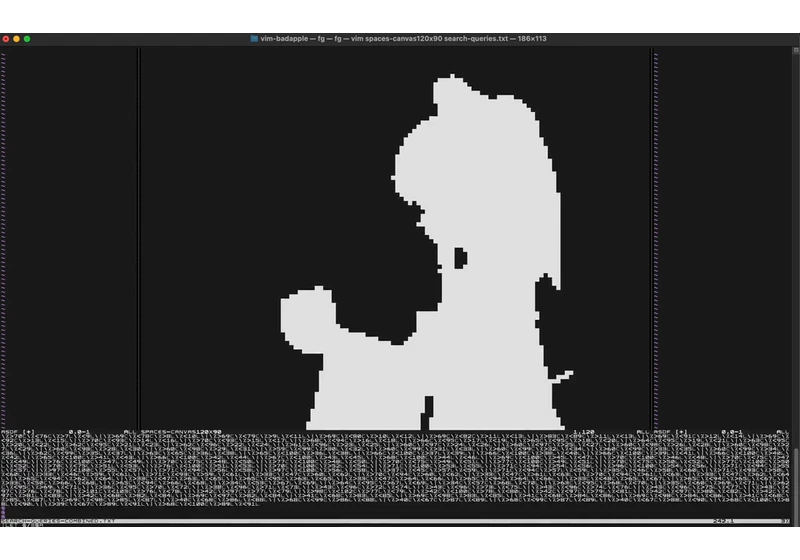
Article URL: https://eieio.games/blog/bad-apple-with-regex-in-vim/
Comments URL: https://news.ycombinator.com/item?id=42674116
Points: 24
# Comments: 4
