Article URL: https://zhihaojia.medium.com/compiling-llms-into-a-megakernel-a-path-to-low-latency-inference-cf7840913c17
Comments URL: https://news.ycombinator.com/item?id=44321672
Points: 73
# Comments: 19
Vytvorené
16d
|
19. 6. 2025, 22:10:04
Ak chcete pridať komentár, prihláste sa
Ostatné príspevky v tejto skupine
")

Article URL: https://www.smithson
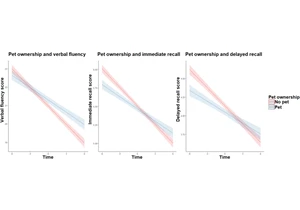
Article URL: https://www.nature.com/articles/s41598-025-03727-9
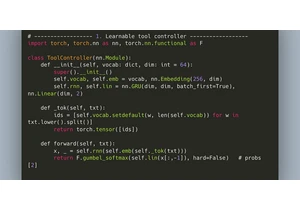


Article URL: https://www.winuae.net/
Comments URL: https://news.ycombinator.com/item?id=4447560

Article URL: https://arxiv.org/abs/2503.14283
Comments URL: https://news.ycombinator.c
